














توضیحات
روش های مختلف جایگزینی داده های مفقود شده
داده های مفقود شده (Missing Value) یکی از موضوعات مهمی است که بی اطلاعی از آن منجر به هدر رفتن وقت و هزینه پژوهشگر می شود و یا حتی نتایج واقعی دچار انحراف و تغییر شود و کسی از این موضوع مطلع نمی شود. چنانچه از روش های قدیمی و مرسوم در نرم افزار spss برای جایگزینی داده های مفقود شده استفاده کنید در برخی موارد نتایج پژوهش تغییر می کند و یا حتی ارتباط واقعی بین متغیرها از بین می رود. روش های متداول و قدیمی که در نرم افزار spss برای مدیریت داده های مفقود شده وجود دارد به شرح زیر است:
- روش حذف نمونه (Listwise deletion)
- روش حذف شرطی (Exclude cases pairwise)
- روش جایگزینی با میانگین (Impute by Mean)
که در ادامه به تشریح هر روش و معایب آن پرداخته می شود.
روش حذف نمونه (Listwise Deletion)
پژوهشگران به راحتی از نرم افزار spss استفاده می کنند و کمتر از این موضوع اطلاع دارند که نرم افزار spss در بیشتر آزمون ها اگر با داده مفقود شده روبه رو شود بطور پیش فرض نمونه ای که حاوی داده مفقود شده است را از تحلیل ها حذف می کند. فرض کنید حجم نمونه 100 نفر باشد و در 50 نمونه هر کدام حداقل یک داده مفقود شده داشته باشند بنابراین نرم افزار spss در این حالت 50 نمونه را از تحلیل ها حذف می کند که این مسئله هم باعث کاهش شدید حجم نمونه می شود و هم به علت از دست رفتن تعدادی زیادی از نمونه ها، از اعتبار علمی نتایج کاسته می شود بنابراین استفاده از این روش توصیه نمی شود مگر اینکه حجم نمونه بقدری زیاد باشد که با کاهش حجم نمونه، تاثیری در اعتبار نتایج ایجاد نشود.
گاهی اوقات ممکن است داده های مفقود شده مربوط به گروه خاص در سوالی خاص باشد که با حذف نمونه ها، نظر این گروه خاص از تحلیل ها حذف می شود و نتایج بدست آمده قابل تعمیم به جامعه بزرگ تر نمی باشد(مثلا افراد با سطح درآمد بالا نخواهند میزان درامد خود را در پرسشنامه اعلام کنند).
روش حذف شرطی (Exclude cases pairwise)
در این حالت در آزمون هایی که متغیر مورد نظر داده های مفقود شده ندارد، هیچ نمونه ای حذف نمی شود و در آزمون هایی که متغیر مورد نظر، داده مفقود شده دارد آن نمونه بصورت کامل از آزمون حذف می شود. در این روش حجم نمونه کمتر کاهش پیدا می کند اما چون نمونه های حذف شده در بعضی از آزمون های آماری وجود دارد و در بعضی از آزمون های آماری وجود ندارد ممکن است نتایج چندین آزمون با یکدیگر تطابق لازم نداشته باشد و ابهامات و انحرافاتی در نتایج کلی ایجاد شود که از وجود نداشتن برخی از نمونه ها در برخی از آزمون ها ناشی می شود.
برای مثال ممکن است در یک پرسشنامه اکثر خانم ها به یک سوال مشخص به علت ترس یا خجالت پاسخ ندهند اما همه آقایون به همه سوالات پاسخ داده باشند. اگر از این روش برای مدیریت داده های مفقود شده استفاده شود ممکن است در بعضی از آزمون های آماری نظرت خانم ها به علت داده های مفقود شده حذف گردد و در برخی از فرضیات که داده مفقود شده وجود ندارد نظرات خانم ها و آقایون کاملا استفاده شود بنابراین نتایج کلی پژوهش ممکن است به دلیل تفاوت دیدگاه خانم ها و آقایون دچار انحراف یا ابهام شود بنابراین استفاده از این روش توصیه نمی شود.
روش جایگزینی با میانگین (Impute by Mean)
برخلاف دو روش قبلی که اقدام به حذف نمونه ها می کردند در این روش مقادیر مفقود شده با میانگین متغیر جایگزین می شود یعنی اگر در یک متغیر 10 مقدار مفقود شده داشته باشیم به جای همه مقادیر مفقود شده مقدار میانگین عینا جایگزین می شود. در این روش چون میانگین به تعداد مقادیر مفقود شده در متغیر تکرار می شود یک مشکل اساسی را ایجاد می کند که آن ضعیف شدن ارتباط بین متغیرها و یا حتی باعث از بین رفتن ارتباط معنادار بین متغیرها می شود.
در هر پژوهش متغیرها با یکدیگر ارتباطات منطقی مثبت یا منفی دارد یعنی با افزایش یا کاهش یک متغیر، سایر متغیرها رفتاری متناسبی(افزایشی یا کاهشی) از خود نشان می دهند اگر بیاییم به جای مقادیر مفقود شد و فقط عدد ثابت میانگین را جایگزین کنیم مقدار تغییرات متغیر کاهش می یابد(انحراف معیار کم می شود) در نتیجه متغیری که مقادیر مفقود شده در آن جایگزین شده است ارتباطش با سایر متغیرها ضعیف تر یا غیر معنادار می شود.
جایگزینی داده های مفقود شده به روش بهینه سازی
روش های متداول و قدیمی را تشریح کردیم و معایب احتمالی هر کدام را توضیح دادیم. ما نیاز به روشی داریم که حجم نمونه را کاهش ندهد، ارتباط بین متغیرها را ضعیف نکند و باعث انحراف در نتایج نشود. برای رسیدن به این حل پایگاه تخصصی تحلیل آماری نرم افزار جایگزینی داده های مفقود شده به روش بهینه سازی را طراحی کرده است. به کمک این نرم افزار بر اساس ارتباط معناداری که بین متغیرها وجود دارد مقادیر مفقود شده با دقت بالایی پیش بینی می شوند که در این صورت ارتباط منطقی موجود بین متغیرها حفظ شود و حجم نمونه ها نیز کاهش پیدا نمی کند. برای درک بهتر مسئله به ذکر یک مثال عملی می پردازیم.
حل یک مثال کاربردی در جایگزینی مقادیر مفقود شده
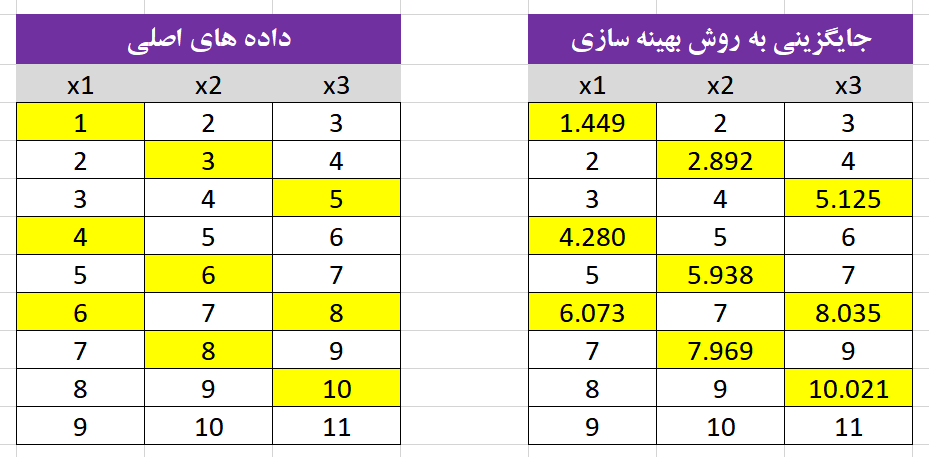
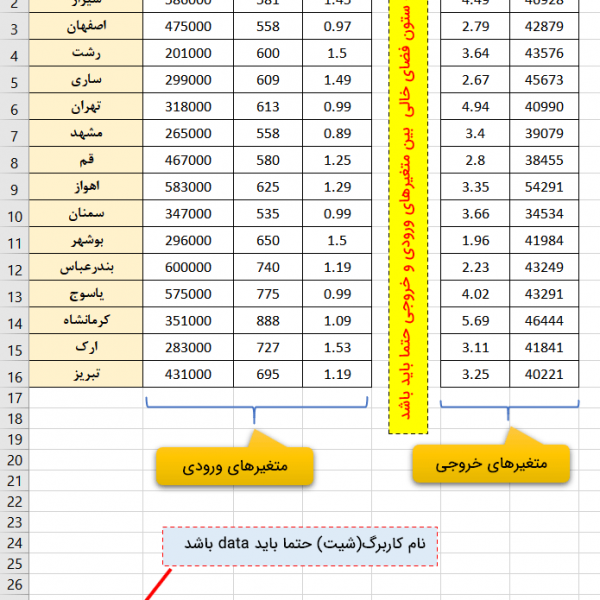
در مثالی که در تصویر زیر آورده شده است 3 متغیر و 9 نمونه وجود دارد. این سه متغیر ارتباطی قوی با یکدیگر دارند تعدادی از داده ها را حذف می کنیم تا داده های مفقود شده، ایجاد شود. سپس از روش های مختلف سعی می کنیم مقادیر مفقود شده را محاسبه و دقت نتایج را با یکدیگر مقایسه کنیم.
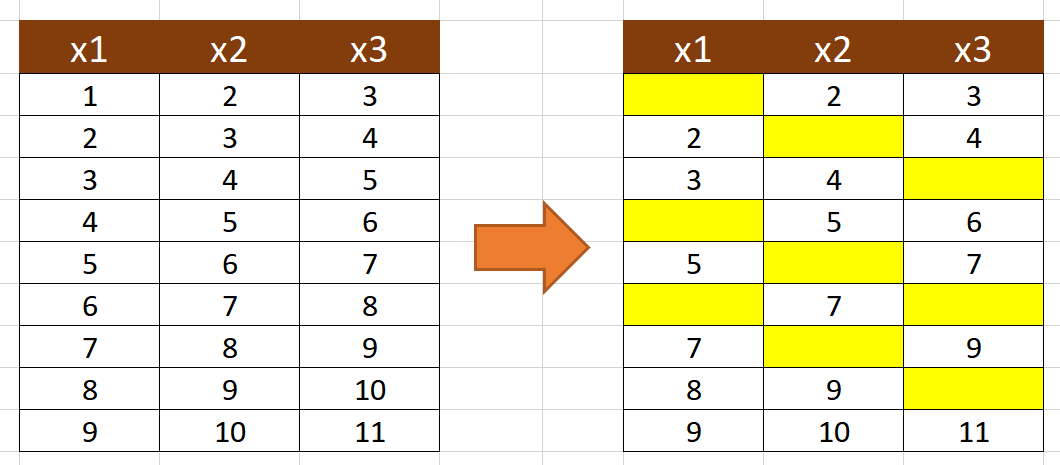
در این مثال اگر بخواهیم از روش حذف نمونه استفاده کنیم در 8 نمونه از 9 نمونه داده مفقود وجود دارد که در این صورت 8 نمونه اول می بایست حذف شود و فقط نمونه آخر در تحلیل باقی می ماند بنابراین این روش قابل استفاده نیست.
در روش حذف شرطی هم باز تعداد نمونه ها کاهش می باید مثلا در ارتباط بین دو متغیر x1 و x2 هفت نمونه اول که شامل داده های مفقود شده هستند حذف می شوند و فقط دو نمونه آخر در تحلیل باقی می ماند بنابراین این روش نیز برای مدیریت داده های مفقود شده قابل استفاده نیست.
در روش جایگزینی با مقدار میانگین، هیچ نمونه ای حذف نمی شود و داده های مفقود شده با میانگین هر متغیر جایگزین می شود که نتایج در جدول زیر آورده شده است.

برای اینکه دقت این روش را بتوانیم ارزیابی کنیم میانگین و همبستگی داده های اصلی(بدون داده مفقود شده) را با میانگین و همبستگی داده هایی که با روش میانگین جایگزین شده اند مقایسه می کنیم. در تصویر زیر نتیجه مقایسه دو حالت آورده شده است.
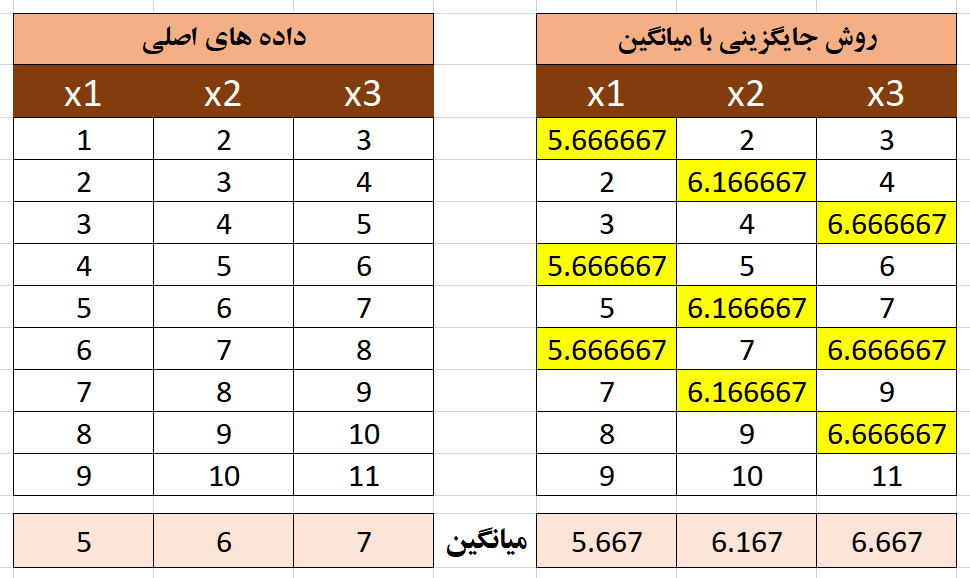
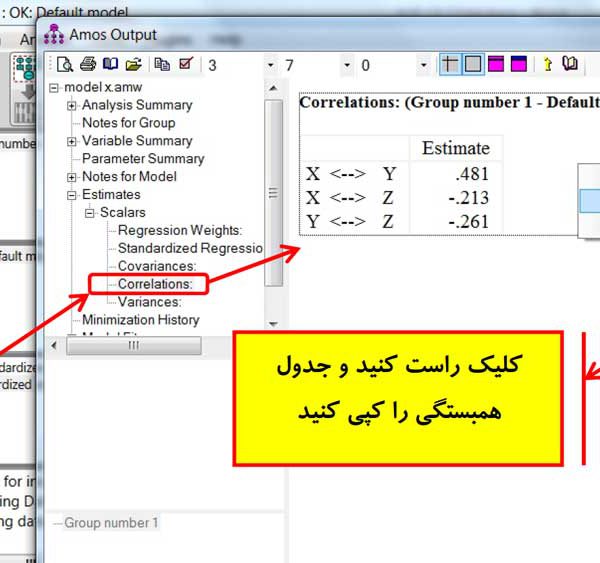
همانطور که در تصویر بالا مشاهده می شود میانگین داده های جایگزین شده با میانگین داده های اصلی تفاوت دارد پس روش جایگزین با میانگین باعث تغییر در میانگین داده های اصلی شده است. در تصویر زیر همبستگی داده های اصلی با همبستگی داده های جایگزین شده مقایسه شده است.
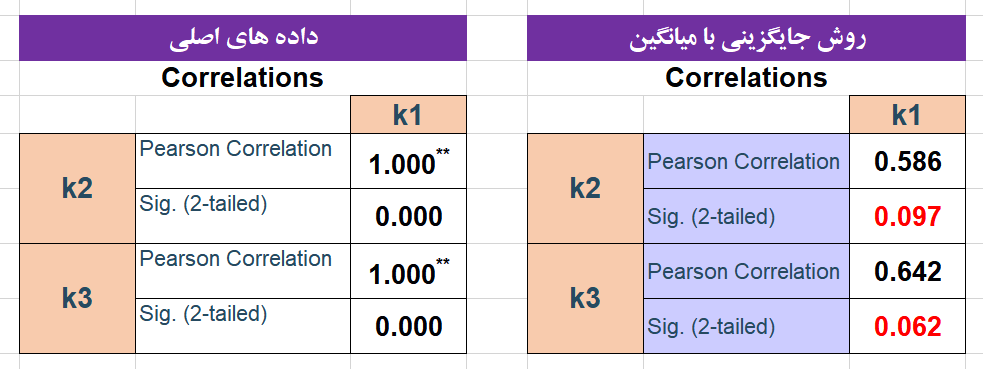
در تصویر بالا به نتایج جالب و تامل برانگیزی رو به رو می شویم. داده های اولیه همبستگی به شدت بالایی با یکدیگر دارند و روابط بشدت معنادار است اما در روش جایگزینی داده های مفقود با میانگین همبستگی به شدت کاهش یافته و از همه مهم تر، ارتباط بین متغیرها معنادار نشده است! بنابراین یکی از معایب روش جایگزینی با میانگین، کاهش ارتباط بین متغیرها و حتی از بین رفتن ارتباط بین متغیرها است در نتیجه این روش توصیه نمی شود.
همانطور که دیده شد روش های مرسوم و قدیمی موجود در نرم افزار spss برای مدیریت داده های مفقود شده روش مناسبی نیستند. در ادامه به توضیح روش بهینه سازی می پردازیم.
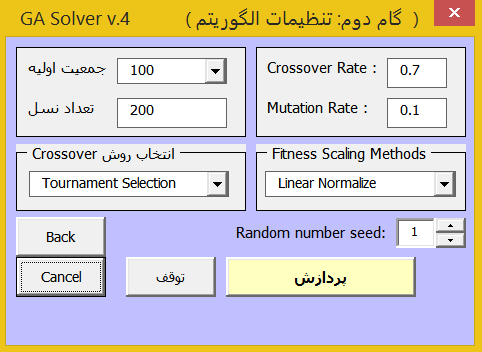
پس از خریداری و نصب نرم افزار Missing Value Optimization ، در قسمت Add-ins اکسل، نرم افزار اضافه می شود که در تصویر زیر نشان داده شده است.
با کلیک بر روی منوی اصلی برنامه پنجره زیر باز می شود.
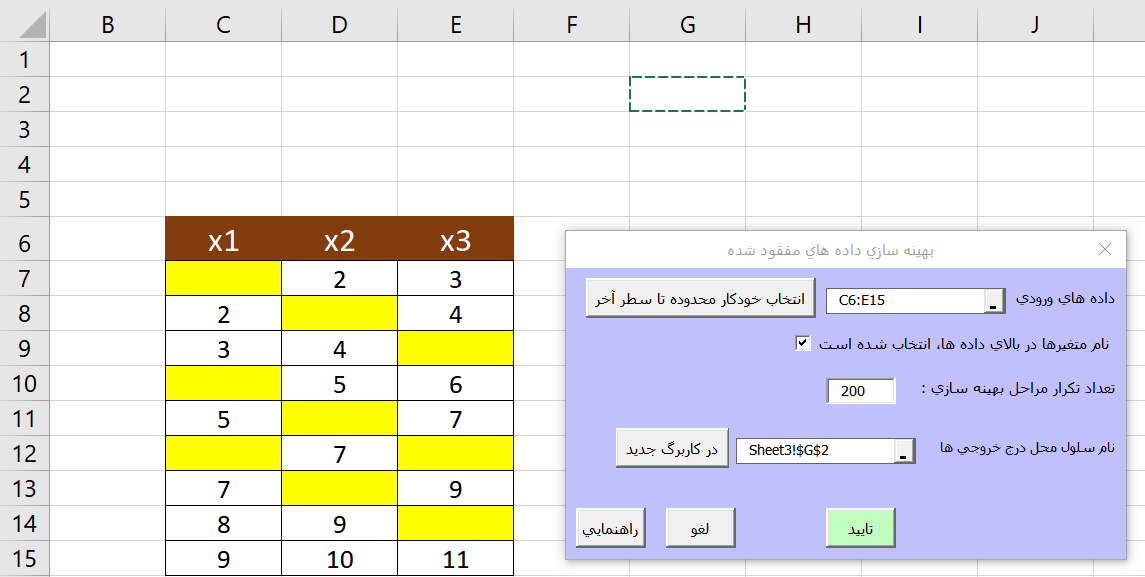
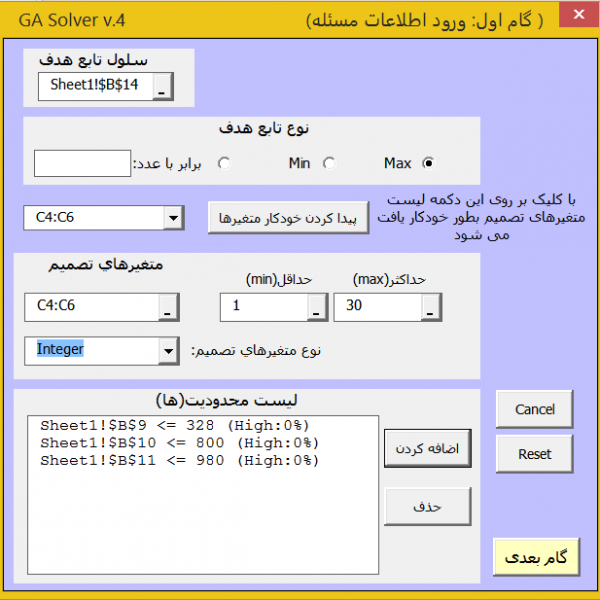
مطابق تصویر بالا داده هایی که در آنها داده های مفقود شده وجود دارد به عنوان ورودی به نرم افزار می دهیم. تعداد تکرار بهینه سازی بطور پیش فرض 200 تکرار است که مقدار مناسبی است. در انتها محلی را که می خواهیم خروجی ها درج شوند مشخص می کنیم و در انتها بر روی دکمه «تایید» کلیک می کنیم تا پردازش داده ها شروع شود سپس خروجی زیر حاصل می شود.
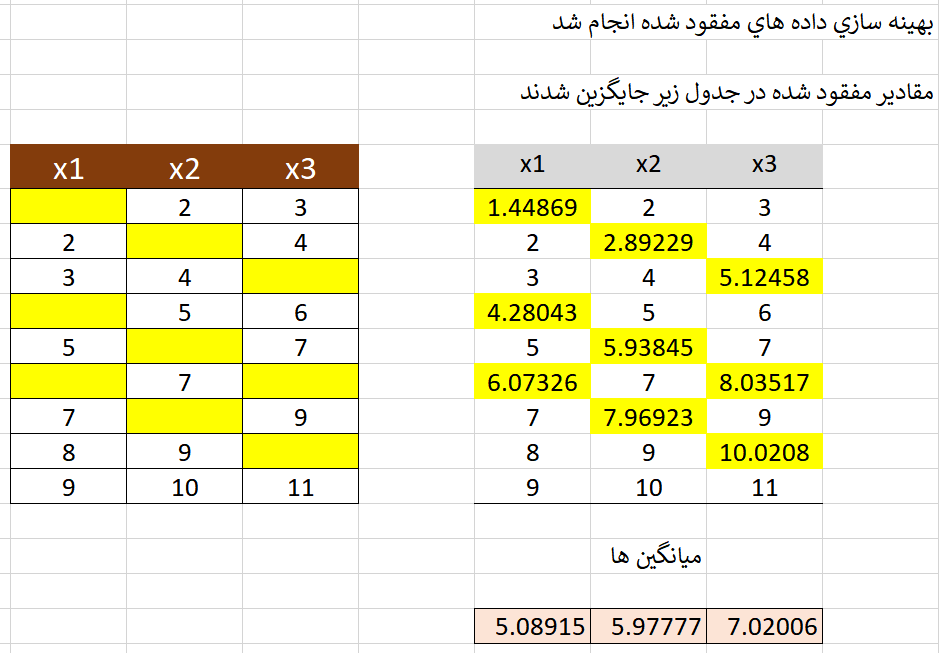
همانطور که نتایج نشان می دهد داده های جایگزین شده به روش بهینه سازی به شدت به داده های اصلی نزدیک است. برای بررسی دقت این روش، میانگین و همبستگی بین متغیرها در حالت اصلی با حالت بهینه سازی با یکدیگر مقایسه می شود.
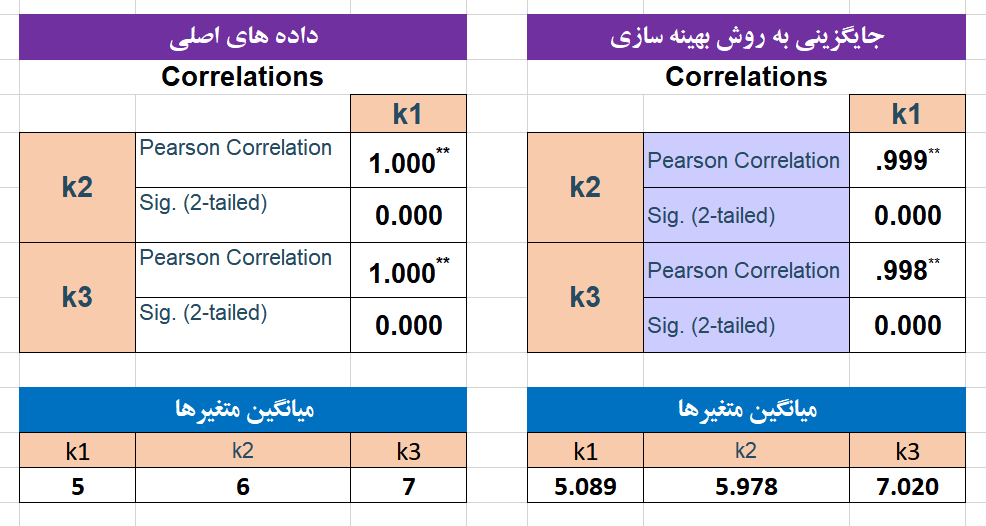
نتایج در تصویر بالا نشان می دهد که همبستگی داده های جدید با همبستگی داده های اصلی در حد یک هزارم اختلاف دارد که دقت بسیار بالایی است یعنی در آزمون های همبستگی، تحلیل رگرسیون و مدل سازی معادلات ساختاری، نتایج داده های جایگزین شده با داده های اولیه بسیار به هم نزدیک است.
علاوه بر این میانگین سه متغیر در داده های اصلی به ترتیب 5، 6 و 7 بوده است و میانگین داده های جایگزین شده به ترتیب 5.089 ، 5.978 و 7.020 است که میانگین داده های بهینه سازی شده هم فقط در حد چند صدم با میانگین داده های اصلی اختلاف دارد که نشان دهنده دقت بسیار بالای روش بهینه سازی است. بنابراین در روش های مقایسه چندگروهی مثل آزمون T، آزمون تحلیل واریانس و تحلیل کواریانس که هدف مقایسه میانگین چند گروه با یکدیگر است می توانید از روش بهینه سازی استفاده کنید و داده های مفقود شده را دقت بسیار بالایی جایگزین کنید.
در تصویر زیر داده های اصلی و داده ای جایگزین شده به روش بهینه سازی مقایسه شده اند. همانطور که مشاهده می شود داده جایگزین شده با داده های اصلی بسیار نزدیک هستند.
چگونه بهترین نتیجه را در جایگزینی داده های مفقود شده بدست بیاوریم؟
اگر می خواهید به روش بهینه سازی داده های مفقود شده را پیش بینی کنید به چند نکته زیر باید توجه کنید تا به نتایجی با دقت بالا دست یابید:
- حداقل باید دو متغیر(دو ستون) داده داشته باشید تا بتوانید از نرم افزار استفاده کنید.
- اگر تعداد متغیرها یا تعداد سوالات پرسشنامه خیلی زیاد است و داده های مفقود شده فقط در یک متغیر وجود دارد می توانید ابتدا یک تحلیل همبستگی بین متغیری که داده مفقود شده دارد با سایر متغیرهای دیگر انجام دهید ببینید متغیری که داده مفقود شده دارد با کدام متغیرها ارتباط قوی و معناداری دارد بعد متغیرهایی که ارتباط معنادار با یکدیگر دارند را به نرم افزار بدهید تا برای شما مقادیر مفقود شده را با دقت بالا پیش بینی کند.




نقد و بررسیها
هنوز بررسیای ثبت نشده است.